RandOm Convolutional KErnel Transform (ROCKET)#
Contributions・サマリー
RandOm Convolutional KErnel Transform (ROCKET) [1] は、1次元Convolutional Kernel(畳み込みカーネル)を用いた時系列特徴量設計手法です。
ランダムにパラメーターを振った畳み込みカーネルを多数用意し、時系列データに適用することで特徴量を得る。この特徴量をもちいて、タスクを解くための軽量なモデルを学習する。
通常のConvolutional Neural Network(CNN) とは違い、カーネルパラメーターの学習が不要なため高速。
時系列分類タスクにおいて、TS-CHIEFやHIVE-COTE, InceptionTime, ProximityForestなどの既存手法よりも高速かつ高精度を示した。
背景#
本記事では、RandOm Convolutional KErnel Transform (ROCKET)と呼ばれる時系列データの特徴量設計手法を紹介します。近年様々な時系列タスクを解くのためのモデルが提案されていますが、学習コストが重く計算に時間がかかることが多くあります。 そこで、ROCKETでは畳み込みニューラルネットワークのパラメーターを直接学習するようなアプローチとは異なり、ランダムなパラメーターをもつ1次元畳み込みカーネルを多数用意し、変換、その組み合わせにより時系列の特徴をとらえます。この変換後の特徴量をもちいて、単純な線形モデルなどを学習することで、トータルの計算コストを低減させます。
ここでは、元論文と同様に時系列分類タスクのためのベンチマークデータセット UCR Time Series Classification Archive [2] を利用した検証と実装を行います。ネットワーク構造の実装はtsai [3](Apache License 2.0) を参考としています。
実装#
主にPyTorchで実装します。
# 主要ライブラリのバージョン
print(f"Python version: {platform.python_version()}")
print(f"PyTorch version: {torch.__version__}")
print(f"Pandas version: {pd.__version__}")
print(f"Numpy version: {np.__version__}")
Python version: 3.11.8
PyTorch version: 2.8.0+cu128
Pandas version: 2.3.2
Numpy version: 2.2.0
データの読み込み#
UCR Time Series Classification Archive はさまざまなドメインで収集された単変量時系列データで、クラス分類のベンチマークとして広く使われています。
今回は、ダウンロードしたデータセットが ../data/UCRArchive_2018 に展開されているとします。データセットのサイズや長さなどの情報がまとまった DataSummary.csv も同じ場所に格納されているとします。
def load_data(
dataroot: Path, dataname: str, mode="train", show_info=False
) -> tuple[np.ndarray, np.ndarray]:
"""
データの読み込み関数
Parameters:
dataroot (Path): データのルートディレクトリへのパス
dataname (str): データの名前
mode (str, optional): 学習用データかテスト用データか(train/test)
show_info (bool, optional): データの情報を表示するかどうか。デフォルトは False。
Returns:
データをロードした結果を返します。
tuple: データとラベルのタプル
"""
if show_info:
datainfo = pd.read_csv(dataroot / "DataSummary.csv", index_col=0)
print("データの情報: ")
display(datainfo[datainfo.Name == f"{dataname}"])
# datalength = int(datainfo[datainfo.Name==f"{dataname}"]["Length"].values)
rawdata = np.loadtxt(
dataroot / dataname / f"{dataname}_{mode.upper()}.tsv",
delimiter="\t",
skiprows=0,
)
data = rawdata[:, 1:]
label = rawdata[:, 0]
return data, label
class RocketDataset(Dataset):
def __init__(self, data: np.array, label: np.array):
"""
データと対応するラベルを入力として、pytorch Datasetを作成
データの次元を(batch_size, channels, sequence_length)
"""
if data.ndim == 2:
data = np.expand_dims(data, axis=1)
self.data = torch.tensor(data).float()
self.label = torch.tensor(label).long()
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.label[idx]
モデル#
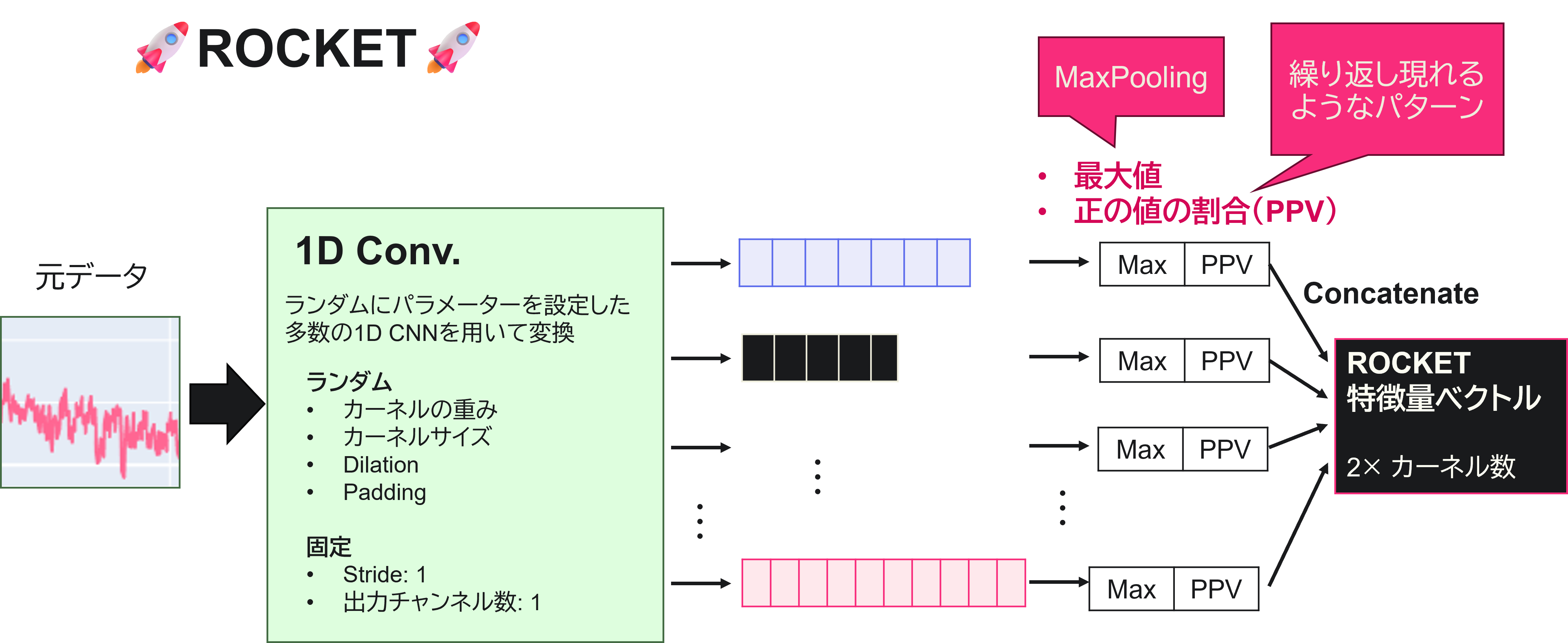
下図にROCKETの概要を示します。例示のため単変量時系列の場合を示していますが、多変量の場合も同様です。
まず、ランダムにパラメーターを振った1次元畳み込みカーネル(1D Conv)を多数(10,000個など)用意します。ここで、1D Convの出力チャンネル数は1次元に固定しているため、出力は1次元ベクトルになります。ランダムパラメーターについては後述します。
次に、元データをそれぞれの1D Convに入力し、変換します。出力はカーネルサイズやdilationなどに応じた長さのベクトルです。
最後に、それぞれのベクトルに対して集約統計量(最大値、正の値の割合)を計算し、結合します。これがROCKET特徴量です。最大値はCNNにおけるMaxPoolingと同様の役割を、PPVは本論文で新たに提案された特徴量で、時系列中の優位なパターンを抽出します。
ランダムパラメーター#
出力チャンネル数を1、strideを1に固定したうえで、その他のパラメーターをランダムにします。それぞれのパラメーターの生成方法は次の通りです。
カーネル重み, \(\mathbf{W}\):
重みベクトル\(\mathbf{W}\)の各値\(w\) を正規分布 \(\mathcal N (0, 1)\) からサンプリング
その後、サンプル平均を引くことで外れ値の影響を低減
カーネルバイアス, \(b\):
一様分布 \(\mathcal U (-1, 1)\)
カーネルサイズ, \(l_{\mathrm{kernel}}\):
[7, 9, 11] からランダム選択
Dilation, \(d\):
指数スケールで一様分布からサンプリング
\(d = \lfloor 2^x \rfloor\)
\(x \sim \mathcal U (0, \log_2\frac{{l_\mathrm{input}} - 1}{l_{\mathrm{kernel}} - 1} )\)
\(l_\mathrm{input}\) は入力系列長
Padding, \(p\):
zero-paddingするかしないかをランダムに選択
選択する場合のpadding量は、\(p=\lfloor\frac{(l_{\mathrm{kernel}} - 1)\times d}{2} \rfloor\). これによりカーネルの中間点に時系列データが含まれることになる。
これらのランダムパラメーターの範囲は、実験的に確かめられており、詳細については元論文をご参照ください。
ROCKETのアーキテクチャー#
以下にROCKETのネットワークを実装しています。
class Rocket(nn.Module):
"""RandOm Convolutional KErnel Transform (ROCKET) model."""
def __init__(
self,
input_length: int,
num_features: int,
num_kernels: int = 10_000,
kernel_lengthes=[7, 9, 11],
verbose=False,
):
super().__init__()
# self.kernels = torch.randn(num_kernels, 3, num_features) / num_features
self.num_features = num_features
self.input_length = input_length
self.num_kernels = num_kernels
# self.to(device=device)
self.verbose = verbose
# カーネル長さが入力長を超えないようにする
kernel_lengthes = [kl for kl in kernel_lengthes if kl < input_length]
convs = nn.ModuleList()
# num_kernels個のカーネルを生成
# それぞれのカーネルのパラメーターはランダムに生成される
for i in range(num_kernels):
ks = np.random.choice(kernel_lengthes)
dilation = 2 ** np.random.uniform(
0, np.log2((input_length - 1) // (ks - 1))
)
padding = int((ks - 1) * dilation // 2) if np.random.randint(2) == 1 else 0
weight = torch.randn(1, num_features, ks)
weight -= weight.mean()
bias = 2 * (torch.rand(1) - 0.5)
layer = nn.Conv1d(
num_features, 1, ks, padding=padding, dilation=int(dilation), bias=True
)
layer.weight = nn.Parameter(weight, requires_grad=False)
layer.bias = nn.Parameter(bias, requires_grad=False)
convs.append(layer)
self.convs = convs
self.kernel_lengthes = kernel_lengthes
def process_one_kernel(self, x, i):
"""
データxとカーネルを指定するindexを受け取る。indexに対応するカーネルにxを入力する。
出力結果の最大値と正の値の割合を返す。
"""
out = self.convs[i](x).cpu()
_max = out.max(dim=-1)[0]
_ppv = torch.gt(out, 0).sum(dim=-1).float() / out.size(-1)
return _max, _ppv
def forward(self, x):
"""
入力時系列に対してカーネルで変換を行い特徴量マップを計算。ROCKETは各特徴量マップから2つの集約統計量(最大値と正の値の割合)を利用する。
Parameters:
x (torch.Tensor): The input tensor. Its shape is (batch_size, num_features, input_length).
"""
# assert x.size(2) != self.input_length, f"Input size is {x.size(2)} but expected {self.input_length}"
_outputs = []
for i in trange(
self.num_kernels, disable=not self.verbose, desc="Transforming"
):
out = self.convs[i](x) # .cpu()
_max = out.max(dim=-1)[0]
_ppv = torch.gt(out, 0).sum(dim=-1).float() / out.size(-1) # 正の値の割合
_outputs.append(_max)
_outputs.append(_ppv)
return torch.cat(_outputs, dim=1) # .cpu()
分類#
ここでは、単純な線形分類器としてリッジ回帰(scikit-learn)をもちいて、ROCKET特徴量のあり・なしで分類精度の比較を行います。
UCRデータセットのうち、一例として論文中で使われている Lightning7 を利用します。
dataroot = Path("../data/UCRArchive_2018")
dataname = "Lightning7"
train_data, train_label = load_data(dataroot, dataname, mode="train", show_info=True)
test_data, test_label = load_data(dataroot, dataname, mode="test")
# 正規化
scaler = StandardScaler()
train_data = scaler.fit_transform(train_data)
test_data = scaler.transform(test_data)
print("データの形状: ", train_data.shape, train_label.shape)
データの情報:
| Type | Name | Train | Test | Class | Length | ED (w=0) | DTW (learned_w) | DTW (w=100) | Default rate | Data donor/editor | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | |||||||||||
| 41 | Sensor | Lightning7 | 70 | 73 | 7 | 319 | 0.4247 | 0.2877 (5) | 0.274 | 0.7397 | D. Eads |
データの形状: (70, 319) (70,)
データ長が319の時系列、70個からなる訓練データで、7クラス分類問題を解きます。
ベースライン#
まずベースラインモデル(ROCKETなし)の実装です。
from sklearn.linear_model import RidgeClassifier
cls_naive = RidgeClassifier()
cls_naive.fit(train_data, train_label)
RidgeClassifier()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| alpha | 1.0 | |
| fit_intercept | True | |
| copy_X | True | |
| max_iter | None | |
| tol | 0.0001 | |
| class_weight | None | |
| solver | 'auto' | |
| positive | False | |
| random_state | None |
# 分類精度
accuracy_score(cls_naive.predict(test_data), test_label)
0.5205479452054794
ROCKETを使わない場合の分類精度は約0.52でした。
ROCKETあり#
ROCKET変換のち、同じ分類器を学習する場合です。
def run_rocket(
model: nn.Module, dataset: Dataset, device="cpu"
) -> tuple[np.ndarray, np.ndarray]:
"""ROCKET変換を実行するための関数
Parameters:
model (nn.Module): ROCKETモデル
dataset (Dataset): 変換するpytorchデータセット
device (str, optional): デフォルトは "cpu"。
Returns:
変換後のデータとラベル
"""
model = model.to(device)
dataloader = DataLoader(dataset, batch_size=256, shuffle=False, drop_last=False)
x_out, y_out = [], []
with torch.no_grad():
for xb, yb in tqdm(dataloader):
outputs = model(xb.to(device))
x_out.append(outputs)
y_out.append(yb)
x_out = torch.cat(x_out).cpu().numpy()
y_out = torch.cat(y_out).cpu().numpy()
return x_out, y_out
# ROCKETモデルの初期化
rocket = Rocket(
input_length=train_data.shape[1],
num_features=1,
num_kernels=10_000,
kernel_lengthes=[7, 9, 11],
verbose=True,
)
# 変換の実行
rocket_feature, rocket_label = run_rocket(
rocket, RocketDataset(train_data, train_label), device="cuda"
)
Transforming: 100%|██████████| 10000/10000 [00:02<00:00, 4395.15it/s]
100%|██████████| 1/1 [00:02<00:00, 2.32s/it]
# 変換後データをもちいて分類器を学習
cls_rocket = RidgeClassifier()
cls_rocket.fit(rocket_feature, rocket_label)
RidgeClassifier()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| alpha | 1.0 | |
| fit_intercept | True | |
| copy_X | True | |
| max_iter | None | |
| tol | 0.0001 | |
| class_weight | None | |
| solver | 'auto' | |
| positive | False | |
| random_state | None |
# テストデータを同じROCKETモデルで変換
rocket_feature_test, rocket_label_test = run_rocket(
rocket, RocketDataset(test_data, test_label), device="cuda"
)
0%| | 0/1 [00:00<?, ?it/s]
Transforming: 100%|██████████| 10000/10000 [00:02<00:00, 4802.95it/s]
100%|██████████| 1/1 [00:02<00:00, 2.12s/it]
# 分類精度
accuracy_score(rocket_label_test, cls_rocket.predict(rocket_feature_test))
0.7123287671232876
ROCKET特徴量を使った場合は約0.71で、使わなかった場合よりも精度が上がっていることが確認できました。
まとめ#
この記事では、ROCKET特徴量について解説を行いました。ROCKETは多数の1D CNNで変換を行う特徴量設計手法です。
ランダムなパラメーターセットをもつ畳み込みカーネルをクラスに持たせる程度で比較的簡単に実装ができ、なおかつ精度向上にも寄与するため、とりあえず試す手法としておすすめです。
時系列分類のための手法として提案されていますが、ただの前処理手法であるため、回帰タスクも同様にして解くことができます。
今回は単純に実装を行っていますが、さらなる高速化のためにはそれぞれのカーネルの計算(forward()のforループ)を並列化したり、データセット自体を分割し並列化することが考えられます。
また、ROCKETをベースとしてパラメーター選択に工夫を凝らし同等精度で高速化を行うMINIROCKET [4] 、重要なカーネルのみを選択するS-ROCKET [5]、辞書法と組み合わせたHydra [6] なども提案されています(MINIROCKETとHydraは、ROCKETと同じ著者)。