スパースモデリング(応用編)#
正則化項をアレンジしよう!#
前回スパースモデリング(基本編)では、基本のスパースモデリングとしてLASSOを題材にスパースな解が得られる原理を視覚的に説明しました。
また厳密にはスパースモデリングではないですが、縮小推定手法としてのRIDGEも紹介し、LASSOとRIDGEをミックスしたスパースモデリングとしてElastic Netの性質を確認しました。
LASSOとElastic Netの対比のように、正則化項\(\Omega(\omega)\)をさまざまにアレンジすることで多様なスパースモデリングが実現できます。そこで本稿は有名なアレンジ手法をいくつか紹介し、その性質と応用方法について確認します。
データ読み込み#
データの読み込みと前処理については前回と同様に行いたいと思います。
ここでは個々の処理について細かく説明しませんので、疑問がある場合はスパースモデリング(基本編)を参照してください。
import warnings
warnings.filterwarnings("ignore")
# pkg_resources関連の警告を特定して抑制
warnings.filterwarnings("ignore", message="pkg_resources is deprecated as an API")
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# matplotlibでは日本語にデフォルトで対応していないので、日本語対応フォントを読み込む
# plt.rcParams['font.family'] = 'BIZ UDGothic' # Windows
# plt.rcParams['font.family'] = 'Hiragino Maru Gothic Pro' # Mac
plt.rcParams["font.family"] = "Noto Sans CJK JP" # Ubuntu
# 使えるフォント一覧は以下のコードで取得できます。
# import matplotlib.font_manager
# [f.name for f in matplotlib.font_manager.fontManager.ttflist]
pd.set_option("display.max_rows", 10)
pd.set_option("display.max_columns", 10)
fpath = "../data/2020413.csv"
df = pd.read_csv(fpath, index_col=0, parse_dates=True, encoding="shift-jis")[::5]
# std < 1e-10の数値列をdropする
drop_list = list(df.describe().loc["std"] < 1e-10)
df = df.drop(columns=df.columns[drop_list])
# 相関行列の要素のうち、条件を満たすものを要素を1、満たしていない要素を0とする、隣接行列を取得する。
# ここでは、後の計算の簡略化のために対角成分も残したまま取り扱う。
# 今回は相関係数の絶対値が0.85より大きいことを条件とする。
Adjacency = np.array(df.corr().abs() > 0.85).astype("int")
# グラフ理論によると隣接行列のべき乗(ただし非ゼロ要素は都度すべて1に変換する)は、適当回数遷移した後に接続している要素を示す。
# 例えばi行の非ゼロ要素のインデックス集合は、i番目の要素と接続している要素の集合となる。
# これを利用して、先ほど定義した隣接行列から、多重共線性の危険性のある列のグループを抽出する
while True:
Adjacency_next = np.dot(Adjacency, Adjacency).astype("int")
Adjacency_next[Adjacency_next != 0] = 1
if np.all(Adjacency_next == Adjacency):
break
else:
Adjacency = Adjacency_next
multicol_list = [np.where(Ai)[0].tolist() for Ai in Adjacency]
# 要素が1つだけのグループ、および重複のあるグループを取り除き、インデックスの最も若い列を残して、それ以外を削減対象とする。
# 削減対象以外の残す列のインデックスを取得する。
extract_list = sorted(list(set(sum([m[:1] for m in multicol_list], []))))
# 多重共線性の危険性を排除したデータセットを得る。
df_corr = df.iloc[:, extract_list]
# 以降では相関係数で次元削減したデータセットを用いる
df = df_corr.copy()
from sklearn.model_selection import train_test_split
X_train, X_validation, y_train, y_validation = train_test_split(
df[df.columns.difference(["気化器圧力_PV"])],
df[["気化器圧力_PV"]],
test_size=0.2,
shuffle=False,
)
from sklearn.preprocessing import StandardScaler
# 正規化を行うオブジェクトを生成
SS_X_train = StandardScaler()
SS_X_validation = StandardScaler()
SS_y_train = StandardScaler()
SS_y_validation = StandardScaler()
# fit_transform関数は、fit関数(正規化するための前準備の計算)と
# transform関数(準備された情報から正規化の変換処理を行う)の両方を行う
X_train[:] = SS_X_train.fit_transform(X_train)
X_validation[:] = SS_X_validation.fit_transform(X_validation)
y_train[:] = SS_y_train.fit_transform(y_train)
y_validation[:] = SS_y_validation.fit_transform(y_validation)
import sys
sys.path.append("../Preprocessing/")
from time_window import time_window_transform
L, M, N, S = 1, 12, 1, 1
X_train_lmns, y_train_lmns = time_window_transform(
X_train.values, y_train.values, l=L, m=M, n=N, s=S
)
X_validation_lmns, y_validation_lmns = time_window_transform(
X_validation.values, y_validation.values, l=L, m=M, n=N, s=S
)
X_train_lmns_flat = X_train_lmns.reshape(
len(X_train_lmns), int(X_train_lmns.size / len(X_train_lmns)), order="F"
)
X_validation_lmns_flat = X_validation_lmns.reshape(
len(X_validation_lmns),
int(X_validation_lmns.size / len(X_validation_lmns)),
order="F",
)
よく使用する関数#
ここも前回同様、学習モデルの性能を確認する関数として score 関数、学習モデルのパラメータを可視化する関数として heatmap 関数、正則化係数とパラメータの推定解の関係を可視化するために path 関数の3つを使用することとします。
個々の関数の詳細はスパースモデリング(基本編)を参照してください。
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
x_tick_label = pd.date_range(
y_validation.index[0], y_validation.index[-1], freq="10min"
)
x_tick_loc = [y_validation.index.get_loc(label) for label in x_tick_label]
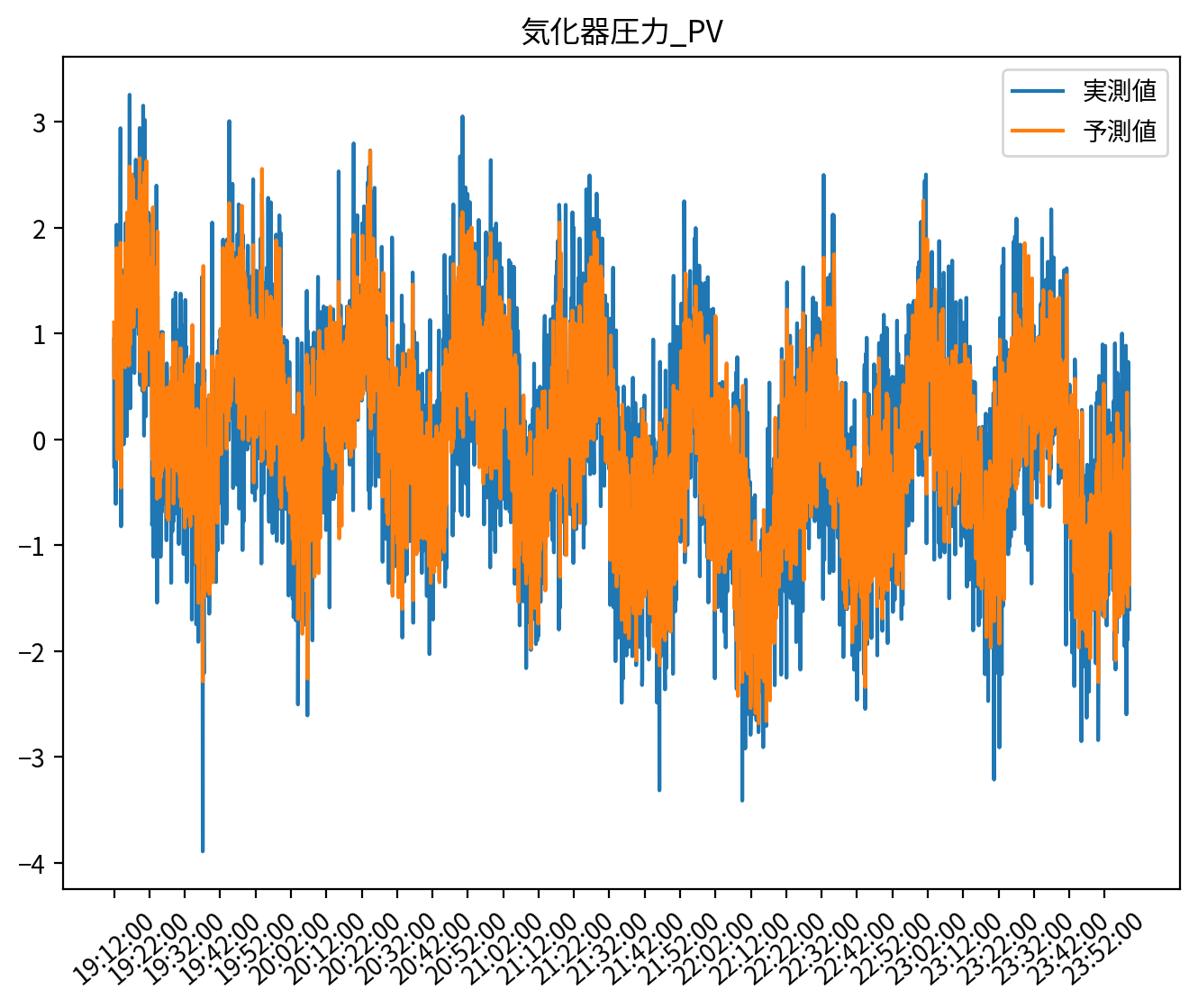
def score(y, y_hat):
mae = mean_absolute_error(y, y_hat)
rmse = np.sqrt(mean_squared_error(y, y_hat))
corr = np.corrcoef(y, y_hat, rowvar=False)[0, 1]
r2 = r2_score(y, y_hat)
print(f"MAE\t: {mae}")
print(f"RMSE\t: {rmse}")
print(f"CORR\t: {corr}")
print(f"R2\t: {r2}")
plt.figure(figsize=[8, 6], dpi=200)
plt.plot(y, label="実測値")
plt.plot(y_hat, label="予測値")
plt.title("気化器圧力_PV")
plt.xticks(x_tick_loc, x_tick_label.strftime("%H:%M:%S"), rotation=40)
plt.legend()
plt.show()
return pd.DataFrame(
np.array([[mae, rmse, corr, r2]]), columns=["mae", "rmse", "corr", "r2"]
)
def heatmap(coef, scale=None):
plt.figure(figsize=[8, 6], dpi=200)
if scale is None:
sns.heatmap(coef.reshape(X_validation.shape[1], -1), center=0, cmap="bwr")
plt.title("各パラメータ $\omega_i$ の推定値")
else:
sns.heatmap(
coef.reshape(X_validation.shape[1], -1),
center=0,
cmap="bwr",
vmin=-scale,
vmax=scale,
)
plt.title(f"各パラメータ $\omega_i$ の推定値:色調範囲[{-scale}, {scale}]")
plt.xticks(
np.arange(M) + 0.5,
[f"-{(m+1)*5}s ~ -{m*5}s" for m in np.arange(M)][::-1],
rotation=10,
fontsize=5,
)
plt.yticks(
np.arange(X_validation.shape[1]) + 0.5,
X_validation.columns,
rotation=0,
fontsize=5,
)
plt.xlabel("窓内の時間遅れ")
plt.ylim(X_validation.shape[1], 0)
plt.grid()
plt.show()
def path(alphas, coefs, best=None):
coefs = coefs[0, M - 1 :: M]
plt.figure(figsize=[8, 6], dpi=200)
plt.xscale("log")
plt.xlim(np.min(alphas), np.max(alphas))
plt.ylim(np.min(coefs), np.max(coefs))
for coef in coefs:
plt.plot(alphas, coef)
if not best is None:
plt.vlines(
best,
np.min(coefs),
np.max(coefs),
linestyles="dashed",
label="最適な正則化係数",
)
plt.xlabel("正則化係数 " + "$\\alpha$" + " [log scale]")
plt.ylabel("各パラメータ $\omega_i$ の推定値")
plt.title("正則化係数に応じた推定解のパス(軌跡)")
plt.legend()
plt.grid()
plt.show()
Adaptive LASSO#
1つめのアレンジはAdaptive LASSOと呼ばれる手法です。
ここで\(\tilde{\omega}\)は適当な重みベクトルで、正則化項のL1ノルム内の\(\omega/\tilde{\omega}\)は各ベクトルの要素間で割り算したベクトルとします。
Adaptive LASSOの正則化項は、LASSOの正則化項内で各パラメータ\(\omega\)に適当な重み\(\tilde{\omega}\)をつけただけのシンプルな構造をしています。
Addaptive(適応的)と呼ばれるのは、適切な重みをつけることで\(\omega\)のうち重要と思われるものを残しやすく、逆に不要と思われるものは0に縮退させる効果があるからです。
仕組みを簡単に説明すると、例えば\(\omega_p\)に対して\(\tilde{\omega}_p\)を大きくすれば\(\omega_p/\tilde{\omega}\)は相対的に小さくなり、逆に\(\tilde{\omega}_p\)を小さくすれば\(\omega_p/\tilde{\omega}\)は相対的に大きくなります。
解きたい最適化問題は\(\omega\)について目的関数を最小化することが目的ですので、\(\omega_p/\tilde{\omega}\)が相対的に小さい\(\omega_p\)よりも大きい\(\omega_p\)を積極的に0に縮小させた方が、全体として最小化に近づきやすくなるはずです。
このようにAdaptive LASSOは、重みに応じて傾斜をつけたLASSOとみなすことができます。
なぜこのような工夫を行う必要があるかと言うと、実は通常のLASSOは変数選択の一致性と推定量の一致性の2つの性質(合わせてオラクル性と呼んだりします)が統計的に担保されていないからです。
サンプルサイズが十分大きいとの仮定で、変数選択の一致性とは非ゼロのパラメータが正しく選択される確率が1となる性質で、推定量の一致性とは非ゼロな係数の推定量が真値に収束する性質のことです。
Adaptive LASSOでは\(\tilde{\omega}\)として最小二乗推定量(などの一致推定量)の絶対値を用いることで、これら変数選択の一致性と推定量の一致性が統計的に担保された推定解を得ることができます。
実際のところサンプルサイズは有限なので、必ずしもこれらの性質を満たした解を得られるとは限りませんが、多くの場合で通常のLASSOよりも的を得た結果を得られる可能性が高い手法と言われています。
sklearn.linear_model にはAdaptive LASSO自体は直接実装されてなさそうですので、ここでは sklearn.linear_model.Lasso を利用して推定する方法を紹介します。
すでに説明したように\(\tilde{\omega}\)は事前に決定された定数重みベクトルであるので、\(\omega^{\prime}:=\omega/\tilde{\omega}\)との置き換えでAdaptive LASSOの最適化問題は次の等価な問題に書き換えることができます。
最後の同値変形では\(X^{\prime}=X\tilde{\omega}\)としました(ここでの積演算は行列積ではなく、\(X\)の\(j\)列目を\(\tilde{\omega}_j\)倍する演算になることに注意)。
すなわち、最初のAdaptive LASSOの最適化問題と、最後のLASSOの最適化問題は等価な問題であるので、これを sklearn.linear_model.Lasso で解くことでAdaptive LASSOの最適解を得ることができます。
実用上は正則化係数\(\alpha\)のチューニングが必要なので、 sklearn.linear_model.LassoCV を用います。
# 重みベクトルを最小二乗推定量の絶対値とする
from sklearn.linear_model import LinearRegression
LinearRegression_model = LinearRegression()
LinearRegression_model.fit(X_train_lmns_flat, y_train_lmns)
omega_tilde = np.abs(LinearRegression_model.coef_)
# 等価なLASSO最適化問題として解く
from sklearn.linear_model import LassoCV
# 訓練データの置き換え
X_train_lmns_flat_prime = X_train_lmns_flat * omega_tilde
# 検証データの置き換え
X_validation_lmns_flat_prime = X_validation_lmns_flat * omega_tilde
Adaptive_LassoCV_model = LassoCV(n_alphas=100, cv=5, n_jobs=-1)
Adaptive_LassoCV_model.fit(X_train_lmns_flat_prime, y_train_lmns)
score_AL = score(
y_validation_lmns, X_validation_lmns_flat_prime @ Adaptive_LassoCV_model.coef_.T
)
MAE : 0.41104365380914015
RMSE : 0.5150836262007694
CORR : 0.857563733161439
R2 : 0.7349970916559785
heatmap(Adaptive_LassoCV_model.coef_)
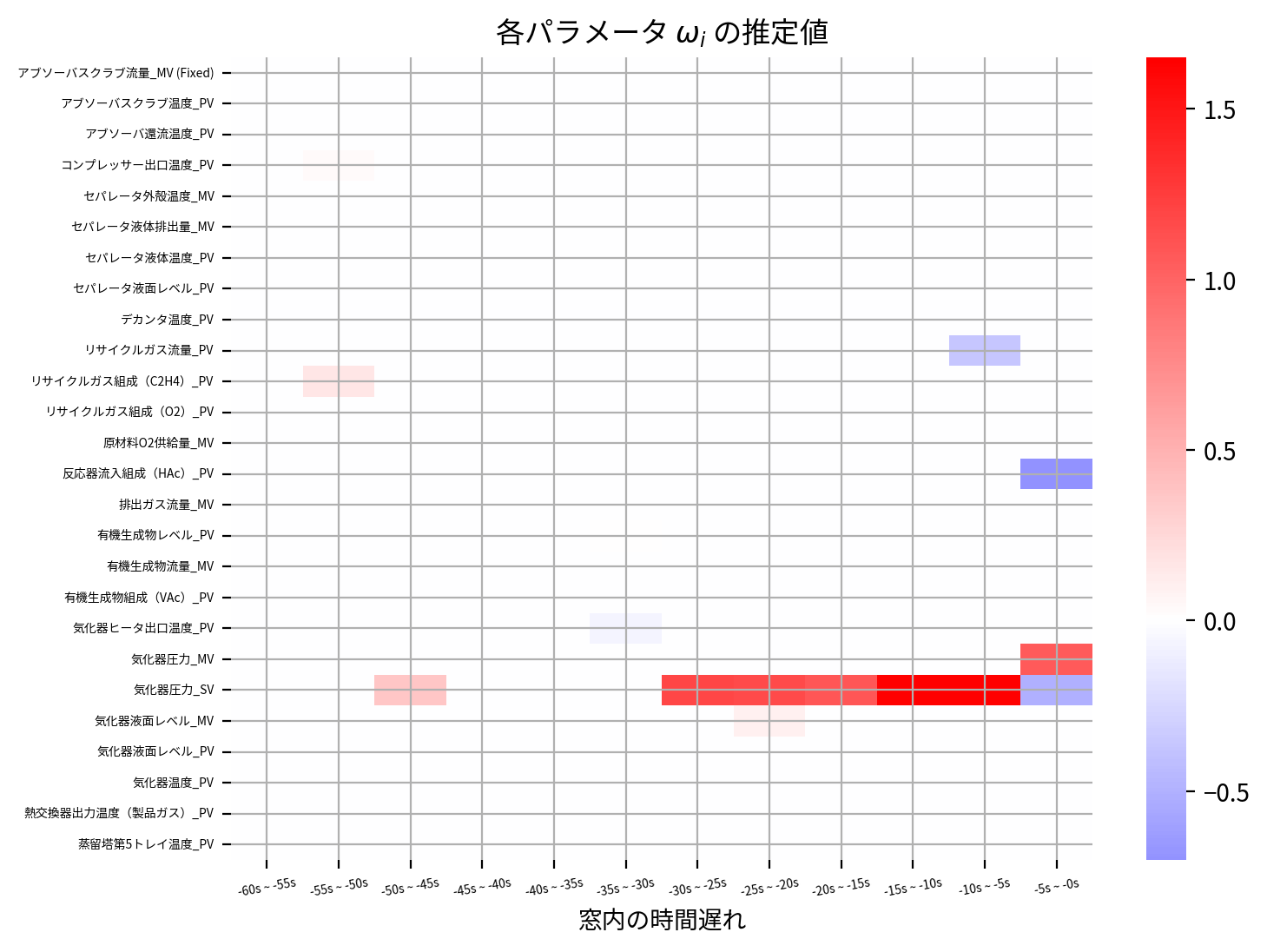
heatmap(Adaptive_LassoCV_model.coef_, scale=0.5)
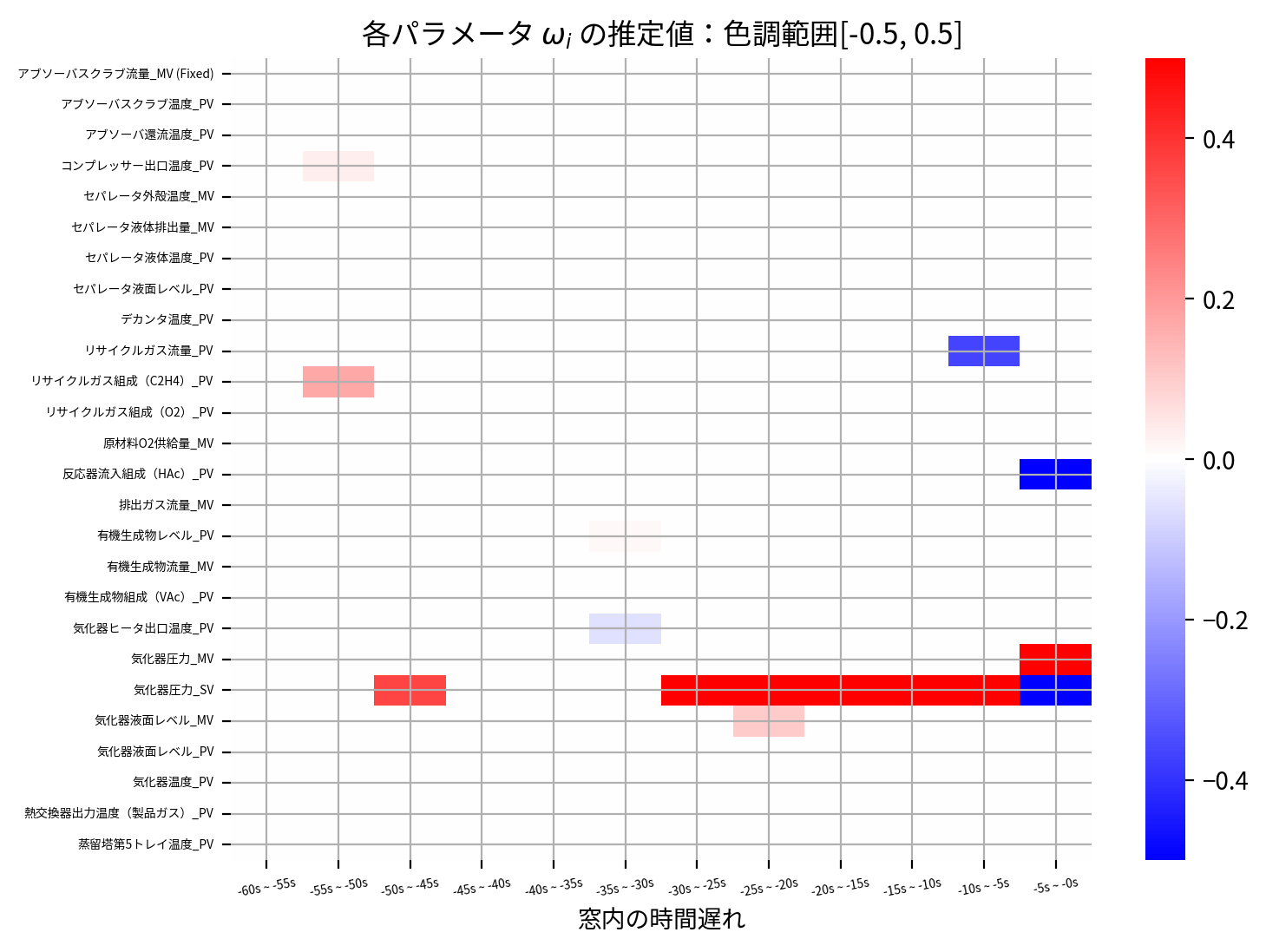
前回スパースモデリング(基本編)のLASSOと比較すると、例えば 反応器流入組成(HAc)_PV の -5s ~ -0s など非ゼロのパラメータは明瞭に非ゼロの値を保ち、逆に0に縮退するパラメータは明確に0に縮退していることが読み取れます。
すなわち、LASSOよりも中途半端に微小量として存在しているパラメータは少なく、全体的に重要なパラメータと重要でないパラメータがはっきり分離した推定解が得られています。
from sklearn.linear_model import lasso_path
alphas, coefs, _ = lasso_path(X_train_lmns_flat_prime, y_train_lmns)
path(alphas, coefs, Adaptive_LassoCV_model.alpha_)
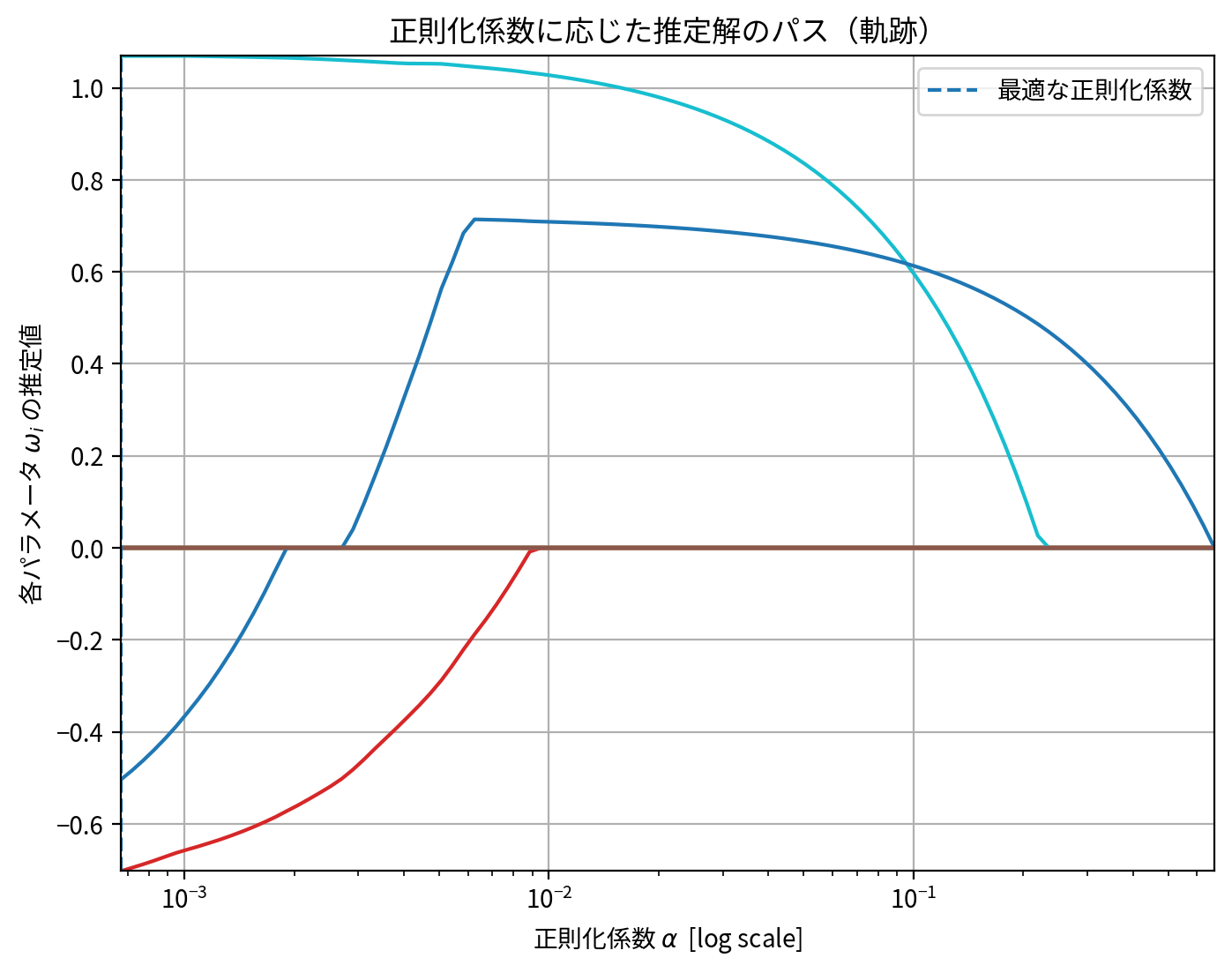
Adaptive LASSOはサンプル数が十分大きい場合は統計的に変数選択の一致性と推定量の一致性が担保されているものの、一般的にはデータは有限サイズなのでサイズに応じて解は不安定になります。
本稿で用いたデータでも正則化係数の増加に応じた濃い青色の解パスの変動にみられるように、一旦負の値から0に縮退するもその後急激に正の値へ増大し再び0に縮退しする不安定なパラメータが存在するようです。
とは言え全体的な傾向をLASSOと比較すれば、不要なパラメータはかなり初期(微小な正則化係数\(\alpha\))の段階で0に削ぎ落とされ、また重要なパラメータについても比較的単調に0に縮退していっていることがわかります。
LASSOでは正則化係数の増加とともに推定解の絶対値が増えたり減ったり不安定な状況も多かったですが、Adaptive LASSOでは統計的にオラクル性が保障されている点からも全体としては比較的安定な推定解が得られていると考えることもできそうです。
Group LASSO#
2つめのアレンジはGroup LASSOと呼ばれる手法です。
ここで\(G\)は\(\omega\)のインデックスの適当な集合で、この\(G\)を用いてパラメータをグルーピングします。
例えば\(\omega\)の1番目と4番目と9番目のパラメータをひとつのグループとしたいとき、これは\(G=\{1,4,9\}\)で表現することとします。
また、\(\mathcal{G}\)はグループ\(G\)全体の集合とし、これは通常解析者によって事前に与えられます。
これらのグループ\(G\)に対して、\(\omega_G\)は\(\omega\)のうち\(G\)に属さないインデックスを持つ要素は常に0とするようなベクトルで、\([\cdot]_p\)をベクトルの\(p\)番目の要素を意味するとすれば、具体的に次のように書き下すことができます。
Group LASSOはこのように事前に定められたグループ構造に沿って、グループごとにパラメータを比較し、グループごとにスパースな解を得ることができる手法です。
すなわち、同じグループに属するパラメータはまとまって0に縮退したり、あるいはまとまって非ゼロの値と推定されたりします。
少し複雑に思うかもしれませんので、簡単な具体例を用いて原理を確認したいと思います。
例えば\(\omega\)は6次元ベクトルであるとし、事前に与えるグループ構造として\(G_1=\{1,3,5\}\)と\(G_2=\{2,6\}\)と\(G_3=\{4\}\)の3つを含む\(\mathcal{G}=\{G_1,G_2,G_3\}\)を考えることとします。
この場合Group LASSOの正則化項は次のように書き下すことができます。
Group LASSOでスパース推定をした結果、例えば\(G_2\)が不要と判断された場合の最終的な推定解は\(\omega=[\omega_1,0,\omega_3,\omega_4,\omega_5,0]^{\top}\)となります。
あるいは\(G_1\)と\(G_3\)が不要と判断された場合は\(\omega=[0,\omega_2,0,0,0,\omega_6]^{\top}\)となります。
このようにGroup LASSOを用いることで、事前に設定されたグループ構造に沿ったスパースな推定解を獲得することができます。
Group LASSOの使い所ですが、例えば解析者の事前知識やノウハウとして変数間にグループが存在すると仮定できる場合に有効です。
例えば今回用いるようなデータセットにおいては、LASSOによって不要なパラメータを削ぎ落とすことに加え、どのセンサー(どのタグ)が相対的に重要であるかが知りたい場合があります。
通常のLASSOでは、個々のパラメータがどのセンサーに属しているかは考慮できず公平にスパース推定するので、このような課題に対する直接的なアプローチはできません。
一方でGroup LASSOでは、同じセンサーに属するパラメータを同一のグループとすれば、グループ構造に沿ったスパース推定がセンサーごとのスパース推定に相当させることができます。
この場合、個々のグループには同一のセンサーに属する時間遅れ違いのパラメータがひとまとめにされています。
Group LASSOは多様な場面で有効な手法であるものの、 sklearn を始めとする python の有名なモジュールには含まれていないのが難点です。
ここでは sklearnに準拠した skglm をインストールして利用することとします。
# jupyter上でインストールする場合はこちら
# !pip install skglm
GroupLasso モジュールでは、パラメータのグルーピング方法として適当な整数でグループ(groups) を指定します。groups はいずれかの方法で指定できます。
単一の整数(
int)入力特徴量を連続したブロックに分割し、各グループのサイズがその整数になる
例: \([\omega_0,\omega_1,\omega_2,\omega_3,\omega_4,\omega_5]\) で
groups=3を指定すると, \(\mathcal{G}_1=\{\omega_0,\omega_1\}, \mathcal{G}_2=\{\omega_2,\omega_3\}, \mathcal{G}_3=\{\omega_4,\omega_5\}\)
整数のリスト(
list of ints)各グループサイズを自由に指定
groups=[2, 4]を指定すると、\(\mathcal{G}_1=\{\omega_0,\omega_1\}, \mathcal{G}_2=\{\omega_2,\omega_3, \omega_4,\omega_5\}\)
リスト of リスト(
list of lists of ints)各グループごとに、明示的に特徴量のインデックスを指定
groups=[[0,2,4], [1,5], [3]]を指定すると、\(\mathcal{G}_1=\{\omega_0,\omega_2, \omega_4 \}, \mathcal{G}_2=\{\omega_1,\omega_5,\}, \mathcal{G}_3 = \{\omega_3\}\)
今回用いるデータは、同じセンサーに属するパラメータを12で指定しているので、groups=12 が簡便です。
念のため、うまくグルーピングできているかどうかをヒートマップで確認します。
ここでは group_ids に格納されている整数値に応じて、異なる色でプロットしました。
# 初期化
group_ids = np.zeros(X_train_lmns_flat.shape[1])
# lmns.pyの仕様と、それをflatにした順番に注意して、同じセンサーに属するパラメータを同一のグループとする
group_ids = np.repeat(np.arange(X_train_lmns.shape[2]), X_train_lmns.shape[1])
# group_idsをヒートマップで可視化
plt.figure(figsize=[8, 6], dpi=200)
sns.heatmap(group_ids.reshape(X_validation.shape[1], -1), cmap="nipy_spectral")
plt.title("各パラメータ $\omega_i$ の所属グループ")
plt.xticks(
np.arange(M) + 0.5,
[f"-{(m+1)*5}s ~ -{m*5}s" for m in np.arange(M)][::-1],
rotation=10,
fontsize=5,
)
plt.yticks(
np.arange(X_validation.shape[1]) + 0.5, X_validation.columns, rotation=0, fontsize=5
)
plt.xlabel("窓内の時間遅れ")
plt.ylim(X_validation.shape[1], 0)
plt.grid()
plt.show()
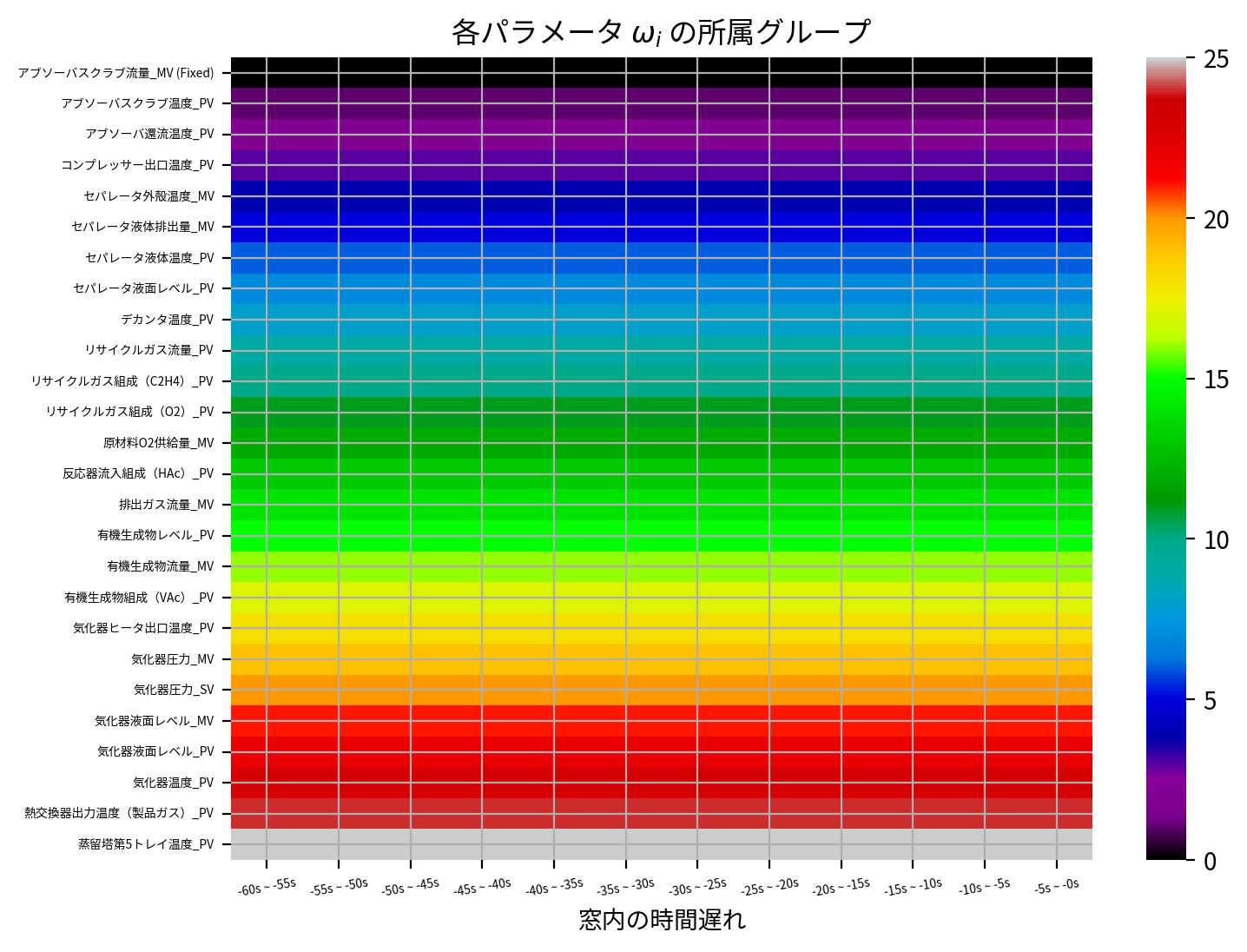
同じセンサーに属する異なる時間遅れのパラメータは同じ色に属していること、すなわち横方向には同色で縦方向にグラデーションができていることから、所望のグルーピングができているようです。
ではこのグルーピングを用いてGroup LASSOでスパースモデリングをしてみます。
skglm はscikit-learnとの互換性がありますので、 sklearn.model_selection.GridSearchCV でラップして、クロスバリデーション による正則化係数のチューニングを行うこととします。
各オプションについての詳細はコード中のコメントアウト or 公式ドキュメントを参照してください。
同様に、GroupLassoの引数の詳細は公式ドキュメント を参照してください。
from skglm import GroupLasso
from sklearn.model_selection import GridSearchCV
# GroupLassoRegressorの引数alpha(正則化係数)の探索リストを指定
param_grid = {"alpha": np.logspace(-3, 0, 10)}
# GroupLassoモデルの定義
# - groups: どのグループに所属するかの指定. 今回は12個ずつに分割
# - alpha: 正則化係数
# - max_iter, max_epochs: 最適化の反復回数
# - tol: 最適化を止める基準
group_lasso_model = GroupLasso(
groups=12,
alpha=1.0, # デフォルト値, GridSearchCVで最適化される
max_iter=50,
max_epochs=1000,
tol=1e-4,
)
# GridSearchCVでクロスバリデーション実行可能なモデルを作る
# - estimator: 学習モデルでここではGroupLassoRegressorを指定
# - param_grid: ハイパーパラメータの探索リスト
# - scoring: 個別のモデルのスコア方法にMSEを指定(他の引数は公式ドキュメント参照)
# - cv: クロスバリデーションの分割数
# - n_jobs: 並列化のジョブ数
Group_LassoCV_model = GridSearchCV(
estimator=group_lasso_model,
param_grid=param_grid,
scoring="neg_mean_squared_error",
cv=5,
n_jobs=-1,
)
# 作成したクロスバリデーション実行可能なモデルにデータを投入して学習
Group_LassoCV_model.fit(X_train_lmns_flat, y_train_lmns)
# ベストなモデルに訓練データをすべて投入して再学習
Group_Lasso_best_model = Group_LassoCV_model.best_estimator_
Group_Lasso_best_model.fit(X_train_lmns_flat, y_train_lmns)
score_GL = score(
y_validation_lmns, X_validation_lmns_flat @ Group_Lasso_best_model.coef_.T
)
MAE : 0.4085107800651649
RMSE : 0.5139863252860817
CORR : 0.8583120564299042
R2 : 0.7361249791717974
score_GL = score(
y_validation_lmns, X_validation_lmns_flat @ Group_Lasso_best_model.coef_.T
)
MAE : 0.4085107800651649
RMSE : 0.5139863252860817
CORR : 0.8583120564299042
R2 : 0.7361249791717974
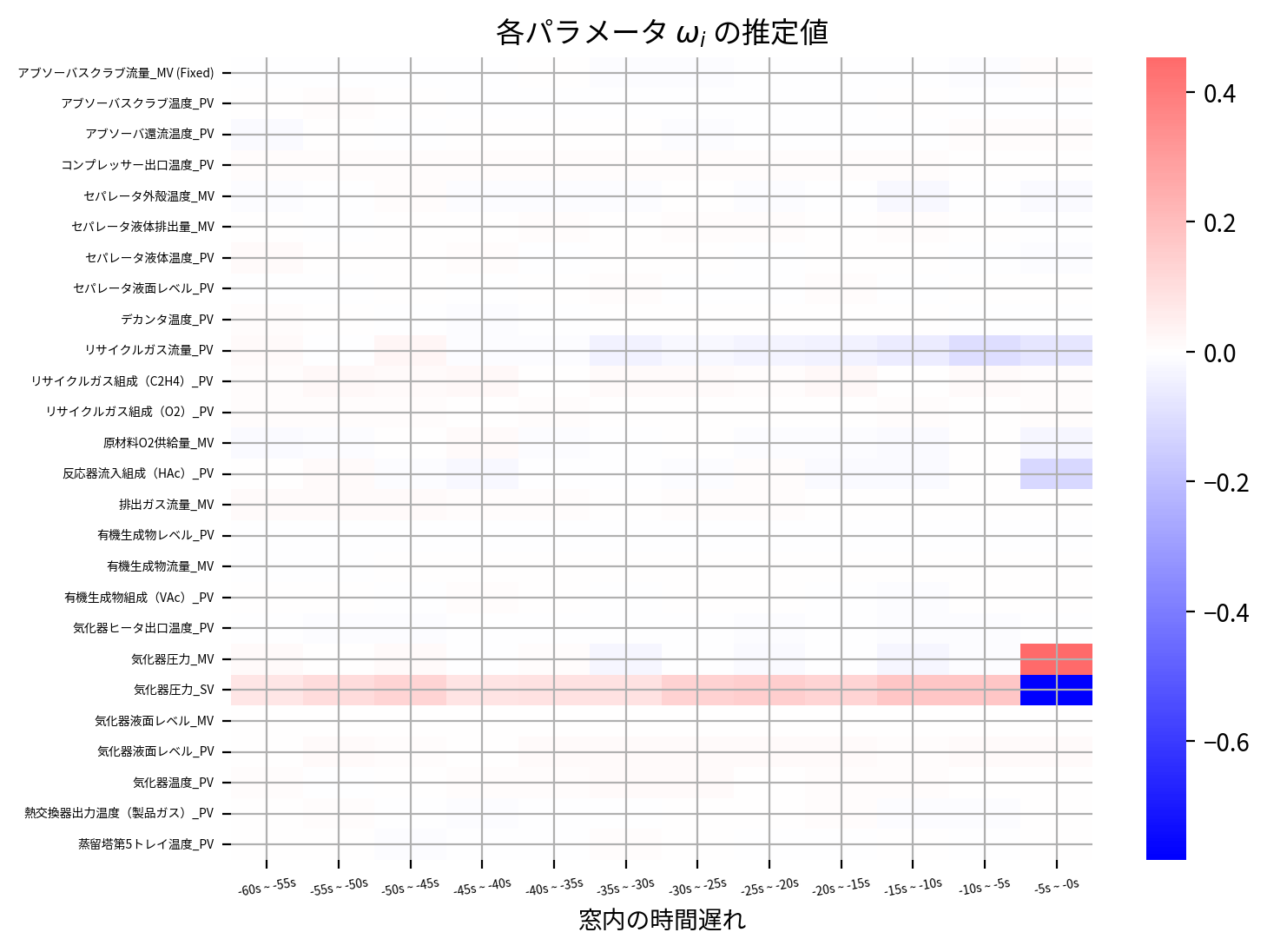
heatmap(Group_Lasso_best_model.coef_)
heatmap(Group_Lasso_best_model.coef_, scale=0.5)
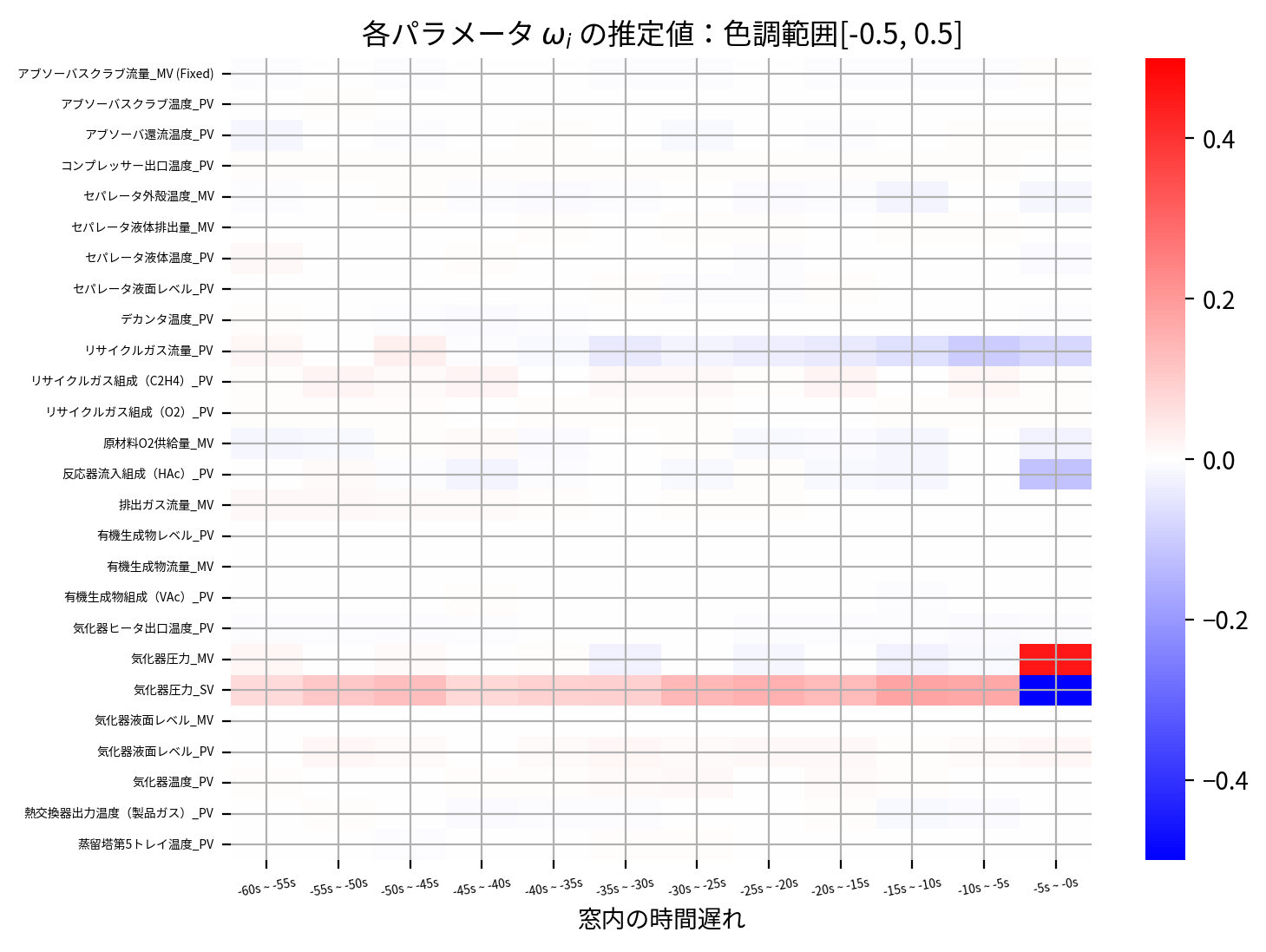
同じセンサーに属するパラメータを同一のグループにするとの制約をつけたため、今回のデータにおいては予測精度は若干落ちているようです。
一方でヒートマップを確認すると、時間遅れ方向に横縞の濃淡がハッキリ確認でき、センサー単位で重要なセンサーと不要なセンサーがより視覚的に判断できます。
このことをもう少し定量的に評価するならば、例えばグループごとのパラメータの絶対値の平均などを比較しても良いかもしれません。
importance = np.mean(
np.abs(Group_Lasso_best_model.coef_.reshape(-1, X_train_lmns.shape[1])), axis=1
)
plt.figure(figsize=[8, 6], dpi=200)
plt.barh(np.arange(X_train.shape[1])[::-1], importance)
plt.title("センサーごとの重要度")
plt.yticks(np.arange(X_train.shape[1])[::-1], X_train.columns, rotation=0, fontsize=5)
plt.ylim(-0.5, X_train.shape[1] - 0.5)
plt.xlabel("パラメータの絶対値の平均")
plt.grid()
plt.show()
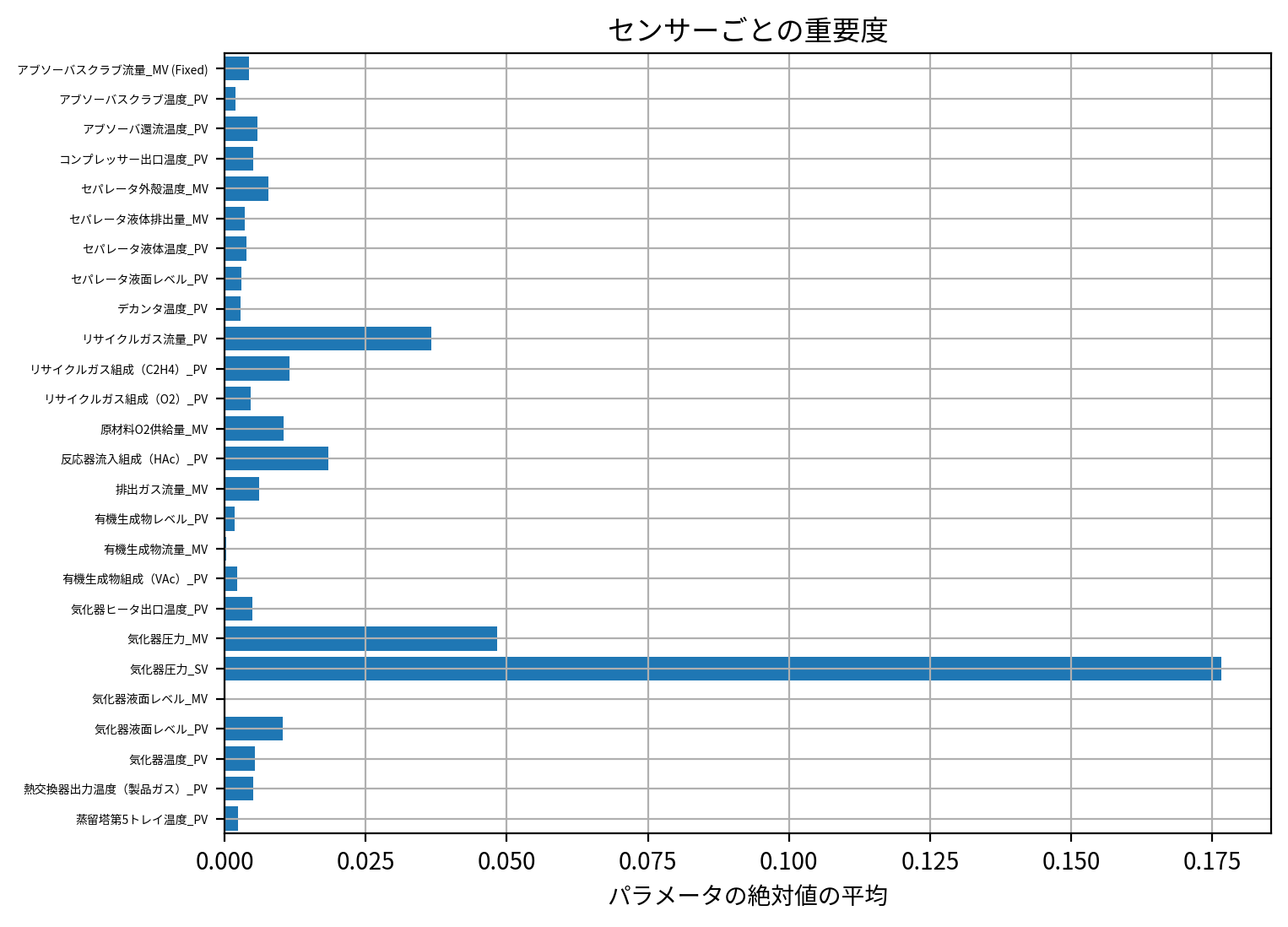
気化器圧力_SV がセンサー全体として最も説明に寄与していると読み取れそうですね。
そしてこのことは他のスパース推定の結果とも整合しそうです(例えばAdaptive LASSOの結果を見ても 気化器圧力_SV が最も説明に寄与していました)。
このようにGroup LASSOを用いることで、事前に設定したグループ構造に沿ってスパースに推定を行うことができます。
さらなる発展として、イノベーションセンターテクノロジー部門ではグループ構造に重複を許したOverlapping group LASSOや潜在変数と確率モデルを導入したLatent Group LASSOなども研究開発しています [Koyama et al. (2019)]。
Group LASSOに関わらずスパース推定全般についての知見も有してますので、気になる方はお気軽にテクノロジー部門までご連絡ください〜。
Fused LASSO#
3つめのアレンジはFused LASSOと呼ばれる手法です。
Fused LASSOの正則化項は一般に2つの項の和となる場合が多いですが、第1項は通常のLASSOの正則化項そのもので、正則化係数\(\alpha_1\)でその強弱がコントロールされています。
問題は第2項で、これはスパースモデリング(基本編)に少し戻ってLASSOの視覚的意味を思い出すと多少理解が簡単になるかもしれません。
すなわちLASSOは絶対値で和を取ることがスパース性を誘導する肝でした。
今回は\(\omega_p-\omega_{p-1}\)ごとに絶対値で和を取っているので、\(\omega_p-\omega_{p-1}\)に関してのスパース推定、つまり\(\omega_p-\omega_{p-1}=0\)を誘導します。
そして\(\omega_p-\omega_{p-1}=0\)は\(\omega_p=\omega_{p-1}\)ですので、これは\(\omega_p\)と\(\omega_{p-1}\)が等しくなるように働きかけます。
従ってFused LASSOは、\(\omega_p-\omega_{p-1}=0\)のようにパラメータの差分に関するスパース推定であるとみなすことができます。
こちらの差分に関する項は正則化係数\(\alpha_2\)によって強弱がコントロールされています。
このようにFused LASSOはパラメータに順序関係があり、隣接したパラメータが等しいか近しい値になるだろうと考えられる場合に有効です。
実は意外にも多くのデータにおいて、Fused LASSOが想定するような仮定は比較的自然に考えられ、使いどころは多々あると思われます。
例えば画像データの隣接ピクセルは同じ被写体の同じ部位なら似たような色調になりますし、時系列データも自己相関によって\(\tau\)時間遅れと\(\tau+1\)時間遅れは同程度説明に寄与すると仮定した方が自然です。
今回用いている時系列データも、隣り合う時間遅れは近しい値になるだろうとの仮定はそんなに的外れではないと思います。
よって同じセンサーに属するパラメータの隣り合う時間遅れに関して、Fused LASSOでスパース推定をしてみることとします。
ただ、Fused LASSOをそのまま適用してしまうと、パラメータ\(\omega\)の隣り合う組みすべてを考慮してしまうので、異なるセンサー間には順序関係がないとの工夫を少し入れます(詳細は後述)。
Fused LASSOも多様な場面で有効な手法であるものの、 sklearn を始めとする python の有名なモジュールには含まれていないのが難点です。
当初はpypiやGitHubでregregという良さそうなモジュールを見つけたので利用を試みたものの、どうにもインストールに難あり、インストールしても所望の動作をしていないようなので、ここでは急遽自前で実装したコードで解析することとします。
細かい解説は本稿のレベルを大きく逸脱するので割愛しますが、こちらのQiitaおよびGitHubの内容を参考にAlternating Direction Method of Multipliers(ADMM)で実装しています。
from sklearn.base import BaseEstimator, RegressorMixin
from sklearn.linear_model import LinearRegression
class FusedLassoRegressor(BaseEstimator, RegressorMixin):
def __init__(
self, D=None, alpha1=None, alpha2=None, rho=0.01, max_iter=10000, epsilon=1e-5
):
self.D = D
self.alpha1 = alpha1
self.alpha2 = alpha2
self.rho = rho
self.max_iter = max_iter
self.epsilon = epsilon
self.coef_ = None
def _soft_threshold(self, vector, threshold):
positive_indexes = vector >= threshold
negative_indexes = vector <= -threshold
zero_indexes = abs(vector) <= threshold
return_vector = np.zeros(vector.shape)
return_vector[positive_indexes] = vector[positive_indexes] - threshold
return_vector[negative_indexes] = vector[negative_indexes] + threshold
return_vector[zero_indexes] = 0.0
return return_vector
def fit(self, X, y):
N, P = X.shape
y = y.reshape(-1, 1)
denominator = (X.T @ X) / N + self.rho * (self.D.T @ self.D)
denominator = np.sum(denominator, axis=0).reshape(-1, 1)
denominator_prime = self.rho
initial_model = LinearRegression()
initial_model.fit(X, y)
omega = initial_model.coef_.reshape(-1, 1)
omega_prime = self.D @ omega.copy()
lambd = np.zeros([len(D), 1])
for iteration in range(self.max_iter):
base = omega.copy()
tmp = (
(X.T @ y) / N
- (lambd.T @ self.D).T
+ self.rho * (self.D.T @ omega_prime)
)
omega = self._soft_threshold(tmp, self.alpha1) / denominator
tmp_prime = lambd + self.rho * (self.D @ omega)
omega_prime = (
self._soft_threshold(tmp_prime, self.alpha2) / denominator_prime
)
lambd += self.rho * (self.D @ omega - omega_prime)
if np.linalg.norm(omega - base) < self.epsilon:
break
self.coef_ = omega.flatten()
return self
def predict(self, X):
y = np.dot(X, self.coef_)
return y
Fused LASSOはパラメータの差分構造に沿った推定を行うため、事前に差分構造を指定する行列を作成し学習モデルに入力する必要があります。
上記コードでは引数 D がそれに相当し、具体的には行列の各行ごとに1つの差分の指定をしています。
例えば\(\omega_2\)と\(\omega_3\)についての差分\(\omega_2-\omega_3\)を入力する場合は、 D の行として\([0,1,-1,0,\ldots,0]\)を追加します。
D はこのように考慮したいすべての差分を入力した行列となり、従って(差分構造の総数)\(\times\)(パラメータの総数)の行列となります。
モジュールは使えませんでしたが、この辺は上記 regreg のドキュメントに沿っていますので適宜参照してください。
今回は同じセンサーに属するパラメータの隣り合う時間遅れに関してFused LASSOを適用したいので、複数のセンサーに跨るような差分構造を入力しないような工夫が必要です。
そこで以下のように、同一のセンサーに属するパラメータ(時間遅れ分合計12個)ついての差分構造を指定するブロック行列 D_block を先に作成し、これをセンサーの個数(合計44個)分対角に配置することで全体の差分構造を指定する行列 D を作成しました。
import scipy as sp
P = X_train_lmns.shape[1]
D_block = (np.diag(np.ones(P)) - np.diag(np.ones(P - 1), k=1))[:-1]
D = sp.linalg.block_diag(*[D_block for _ in range(X_train_lmns.shape[2])])
ここでも D が正しく指定できているかは、ヒートマップを用いて確認すると便利です。
ただ今回のデータに関してはすべてプロットすると潰れて見にくくなるので、最初の50\(\times\)50行列のみプロットしてみます。
plt.figure(figsize=[8, 6], dpi=200)
sns.heatmap(D[:30, :30], center=0, cmap="bwr")
plt.title("差分構造を指定する行列$D$")
plt.xticks(
np.arange(30) + 0.5,
[f"$\omega{p+1}$" for p in np.arange(30)],
rotation=10,
fontsize=5,
)
plt.yticks(
np.arange(30) + 0.5,
[
X_train.columns[:3][(p - 2) % 10] if p in np.arange(2, 30, 11) else ""
for p in range(30)
],
rotation=85,
fontsize=7,
)
plt.xlabel("各パラメータ $\omega_i$")
plt.ylim(29, 0)
plt.grid()
plt.show()
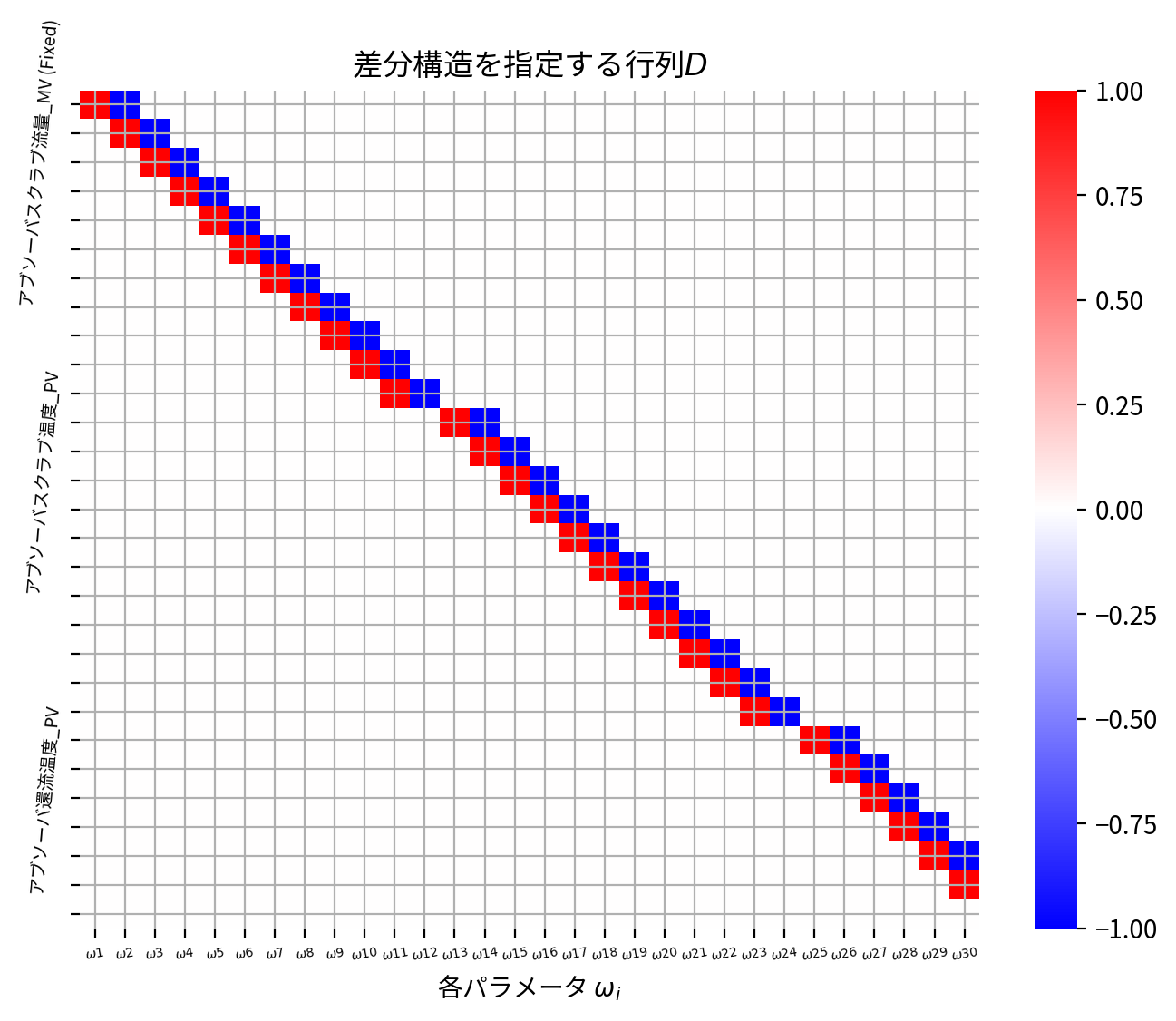
行列 D のヒートマップでは、赤色は1で青色は-1を意味しています。
パラメータ\(\omega\)のうち、最初の12列\(\omega_1\)〜\(\omega_{12}\)がセンサー アブソーバスクラブ流量_MV (Fixed) に関する時間遅れパラメータですので、最初の11行目までが当該センサー アブソーバスクラブ流量_MV (Fixed) に関する差分構造です。
同様に アブソーバスクラブ温度_PV 、 アブソーバ還流温度_PV 、…と続いていくのですが、複数センサーに跨る隣接パラメータはうまく差分構造としての指定から外せてることが確認できます。
この差分構造を指定して、Fused LASSOの数値計算を行うにあたり、例によって sklearn.model_selection.GridSearchCV でラップすることで正則化係数\(\alpha_1\)と\(\alpha_2\)のチューニングを行います。
from sklearn.model_selection import GridSearchCV
# FusedLassoRegressorの引数alpha1とalpha2の探索リストを指定
param_grid = {"alpha1": np.logspace(-2, 0, 5), "alpha2": np.logspace(-2, 0, 5)}
# GridSearchCVでクロスバリデーション実行可能なモデルを作る
# - estimator: 学習モデルでここではFusedLassoRegressorを指定
# - param_grid: ハイパーパラメータの探索リスト
# - scoring: 個別のモデルのスコア方法にMSEを指定(他の引数は公式ドキュメント参照)
# - cv: クロスバリデーションの分割数
# - n_jobs: 並列化のジョブ数
Fused_LassoCV_model = GridSearchCV(
estimator=FusedLassoRegressor(D=D), # パラメータの差分構造
param_grid=param_grid,
scoring="neg_mean_squared_error",
cv=5,
n_jobs=-1,
)
# 作成したクロスバリデーション実行可能なモデルにデータを投入して学習
Fused_LassoCV_model.fit(X_train_lmns_flat, y_train_lmns)
# ベストなモデルに訓練データをすべて投入して再学習
Fused_Lasso_best_model = Fused_LassoCV_model.best_estimator_
Fused_Lasso_best_model.fit(X_train_lmns_flat, y_train_lmns)
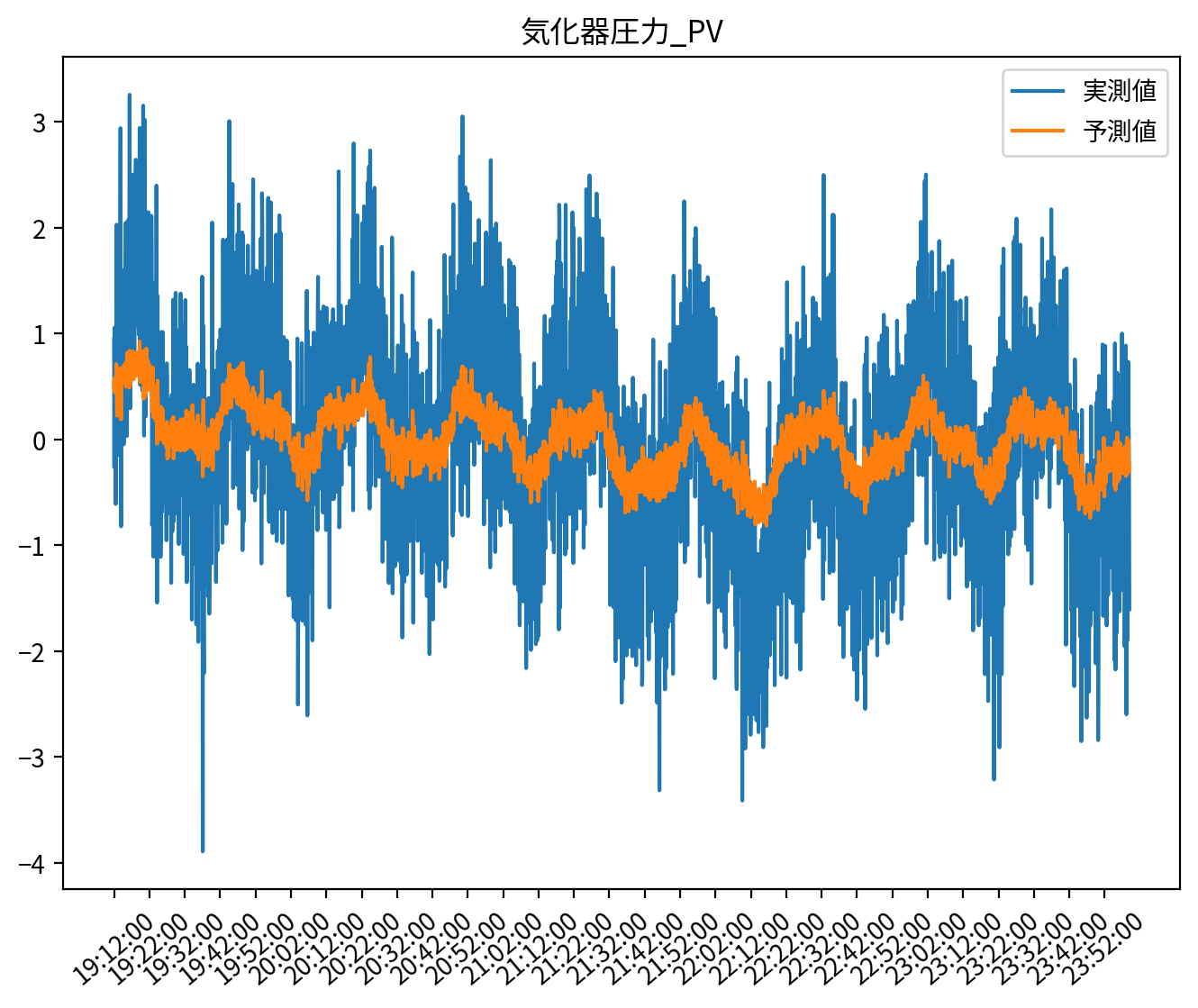
score_FL = score(
y_validation_lmns, X_validation_lmns_flat @ Fused_Lasso_best_model.coef_.T
)
MAE : 0.6315045792369717
RMSE : 0.7871369080690724
CORR : 0.7848740640684354
R2 : 0.38113530991846256
heatmap(Fused_Lasso_best_model.coef_)
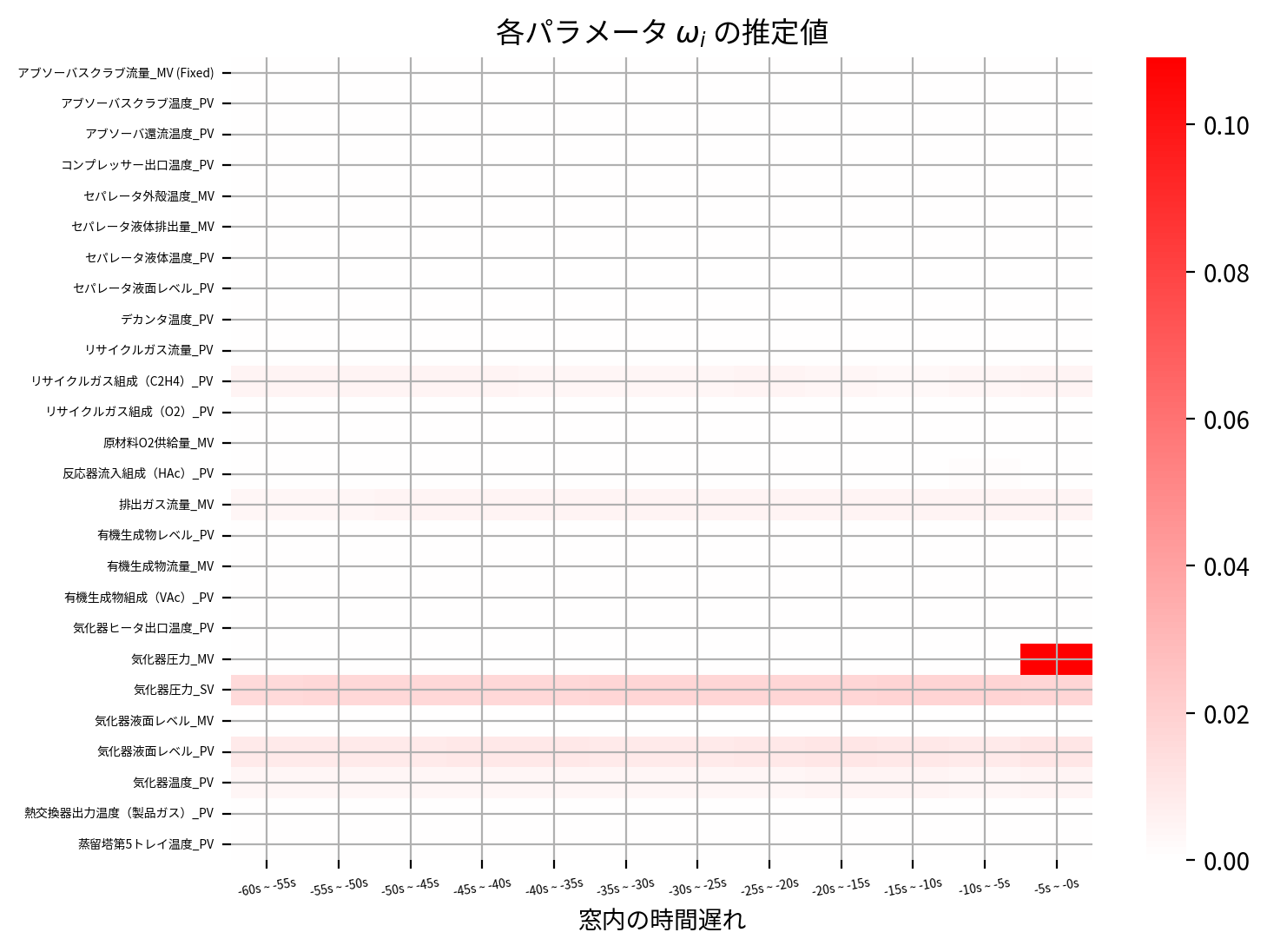
heatmap(Fused_Lasso_best_model.coef_, scale=0.5)
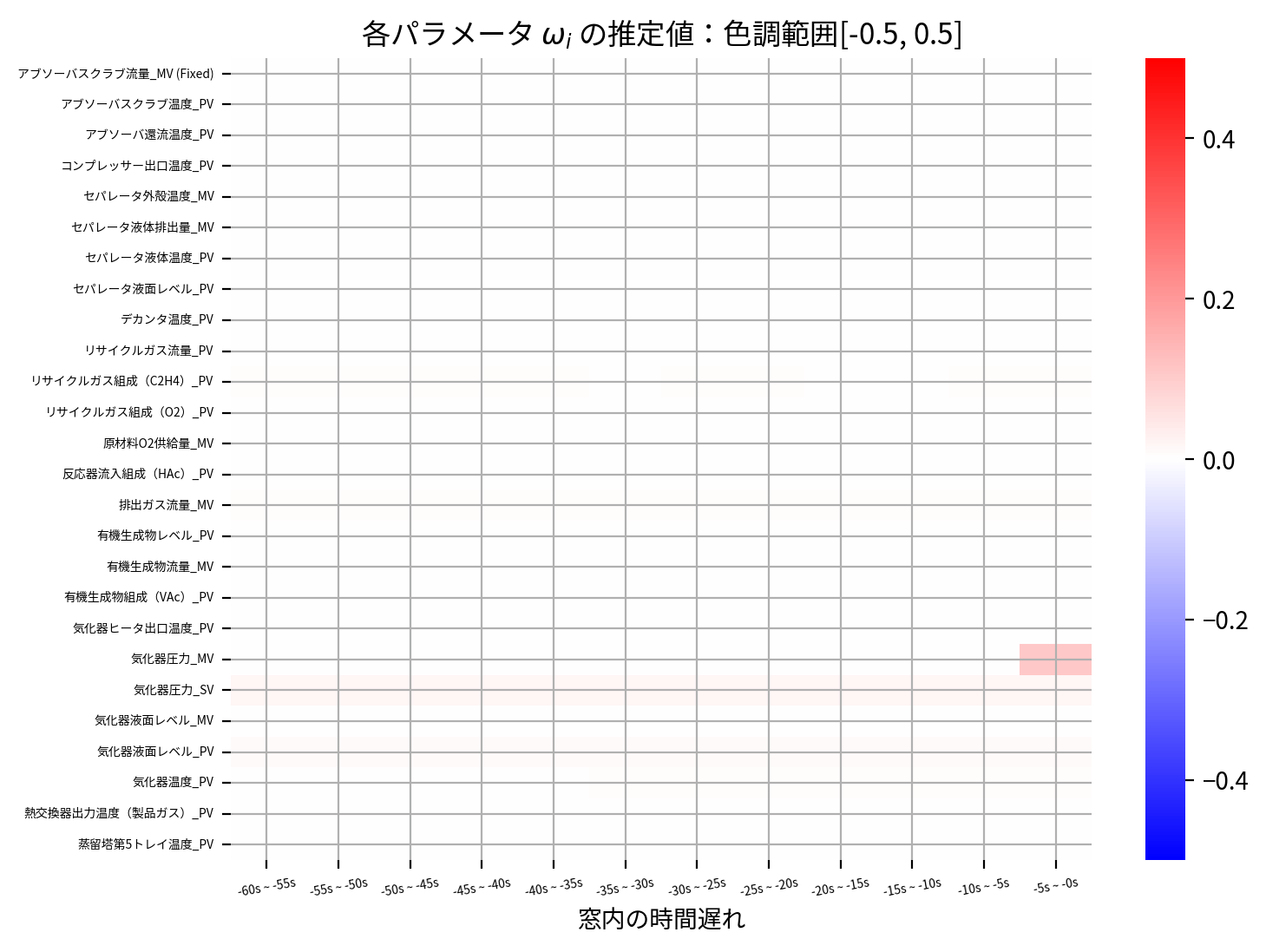
またまた精度自体は落ちてしまったようですが、ヒートマップを見てわかるように時間的に隣接し合うパラメータは近しい値になるように推定され、時間方向に対して非ゼロパラメータの値は滑らかに変化しています。
もちろん程度問題はありますが、例えば時系列データにおける自己相関などパラメータ間に強い相関がある場合には、スパースモデリング(基本編)のLeast Squares Methodのヒートマップのように愚直に回帰すると正の値と負の値を交互に繰り返したような推定となることが多々あります。
これは時間的に隣り合う変数同士の相関が非常に強いため、実際には目的変数に極端に影響を与えていないにも関わらず、そのことを学習モデルでは前後の正負の打ち消し合いで表現している可能性があり、過学習を引き起こしている危険性があります。
Fused LASSOはこのような正の値と負の値を交互に繰り返しを抑制し隣接パラメータが滑らかに変化するように作用するので、適切に使用することでデータに対する自然な学習モデルを獲得することができます。
小括#
本稿ではスパースモデリング(基本編)に引き続き、スパースモデリングのさまざまな応用手法について紹介しました。
なかなか技術的難易度の高い箇所もあったかもしれませんが、正則化項の形状に応じて多種多様なスパース性を誘導することができる、スパースモデリングは奥が深くて自由度の高い世界なんだと感じていただければ幸いです。
さらなる深淵に挑戦してみたい方は、ぜひ特集記事スパースモデリング(発展編)も読んでみてください!
またスパース推定の数理的な理解にはスパース性に基づく機械学習がオススメです。
参考文献#
機械学習の炊いたん。 CHAPTER 6 スパース推定の数理 〜オッカムはウィリアムだろ常考〜